AI 辅助编程(也常被叫做 vibe coding)可以理解成:让 AI 帮你查资料、拆任务、写/改代码、跑验证,你负责做决定和验收。
入门只需要弄清两件事:
- 客户端怎么选:CLI / IDE Code 扩展 / AI IDE。
- API 怎么理解:模型、接口形态、以及额度/限额。
本文主要以海外主流工具为例,国内的ai产品,有些还是挺不错的,也便宜很多,有时间再另写一篇介绍。
第一部分:客户端(CLI / IDE 扩展 / AI IDE)
选型:
- 你比较喜欢在终端里干活:选 CLI,比如 Claude Code、Codex,生态强大、可定制化,不过对新手不太友好。
- 你想仍然在现有 IDE 里使用 AI 开发:选 IDE 扩展,比如 GitHub Copilot、Cline、Augment Code,交互方便、不用换IDE,但生态较差、更新慢些。
- 你想要更强的ai coding体验:试试 AI IDE,比如 Cursor、Google Antigravity,兼顾交互和功能,但是要换个IDE、环境。
CLI 部分
对于Cli,新手可以先直接安装cc-switch,无脑配置。
cc-switch
- 谁做的:社区开源(cc-switch 项目)。
- 特点:专门用来给多个 CLI 工具做“统一管理/一键切换 API 供应商”(Claude Code、Codex、Gemini CLI 等),非常适合经常在官方/中转站之间切换的人。
- 安装:到 Releases 下载对应平台的安装包即可。
仓库:https://github.com/farion1231/cc-switch
Claude Code
- 谁做的:Anthropic。
- 特点:终端里的 coding agent,可读仓库、改文件、跑命令(一般会有权限/确认步骤)。
- 安装:
macOS\Linux
curl -fsSL https://claude.ai/install.sh | bash
Windows PowerShell
irm https://claude.ai/install.ps1 | iex
文档:https://code.claude.com/docs/en/quickstart
OpenAI Codex CLI
- 谁做的:OpenAI(开源,Rust 实现)。
- 特点:本地终端 agent,可在指定目录读/改/运行代码;Windows 支持通常属于实验/建议用 WSL。
- 安装(npm):
npm i -g @openai/codex
仓库/说明:https://github.com/openai/codex
IDE 扩展 部分
门槛很低,大部分都有免费额度,新手建议先使用一段时间的IDE扩展入门
Cline
- 谁做的:社区开源(是Roo Code、Kilo Code他们的爹)。
- 特点:工作流/功能比较完善(Plan/Act:先给计划、再执行),操作相对简单,很适合新手入门。可以直接使用自定义的API 供应商。
- 安装:IDE 扩展市场搜索 “Cline” 安装即可。
GitHub Copilot
- 谁做的:GitHub(Microsoft)。
- 特点:主打代码补全 + 对话式辅助,也支持 Agent/代理模式 处理更完整的任务流,适合在 VS Code 里“边写边问”。通过OAI扩展来自定义API 供应商。
- 安装:VS Code自带的。
Augment Code
- 谁做的:Augment(商业产品)。
- 特点:强调“上下文引擎”(大仓库更省心),更偏团队/工程化使用;付费为主,并且通常不能自定义 API 供应商。(但社区有大佬开发的开源插件,可以偷偷用)
- 安装:IDE 扩展市场搜索 “Augment” 安装即可。
定价(了解额度模型):https://www.augmentcode.com/pricing
AI IDE 部分
Cursor
- 谁做的:Cursor。
- 特点:把 Chat/Composer/Agent 做进 IDE,常见卖点是“代码库索引 + 任务式 agent”。AI IDE 先行者,现在各方面优势不大了。
- 安装:官网下载并安装即可。
Google Antigravity
- 谁做的:Google。
- 特点:更偏 “agent-first”,有类似“任务指挥台”的界面,适合并行跑多个任务。可以通过学生认证、家庭组,白嫖个pro会员,性价比高。
当然也可以反代出来做为api,但是现在封号特别严 - 安装:按官方引导下载客户端并登录,需要稳定的外网环境。
第二部分:API(模型 / 形态 / 来源 / 额度)
API是上述客户端链接的供应商模型服务,有以下几个方面:用什么模型、怎么调 API、从哪里接入、怎么理解额度。
1) 模型怎么选
-
gpt-5.2:来自Openai,通用主力,逻辑强,比较细致。
- 适合:日常编码、重构、改bug、写脚本、生成测试。
-
gemini 3.1:来自谷歌,偏多模态(看图、读文档、还原 UI。
- 适合:读设计稿/截图/表格文档、从 UI 截图还原组件、处理长文档信息。
-
claude opus 4.6:来自Anthropic,偏长文本理解、写作、编码。
- 适合:把需求讲清楚、写技术方案/说明文档、整理复杂上下文、干活快。
- opus很贵,可以用便宜些的claude sonnet 4.6
2) 常见 API 格式(curl 示例)
这部分使用时,一般不需要管,但要知道它们的不同。避免买完API服务,才发现格式对不上,得换个客户端。
OpenAI Chat
最通用的格式,也常被 OpenAI-compatible 中转复用。一般第三方中转、Openai模型的网页聊天,都可以用这个接口。
curl https://api.openai.com/v1/chat/completions \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-5.2",
"messages": [
{"role": "system", "content": "你是一个严谨的编程助手"},
{"role": "user", "content": "用一句话解释什么是 token"}
]
}'
OpenAI Cli(/v1/responses)
OpenAI 更推荐的“统一接口”(相对
/v1/chat/completions功能支持更好)。比如Codex使用的就是这个接口。
curl https://api.openai.com/v1/responses \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-5.2",
"input": [
{"role": "system", "content": "你是一个严谨的编程助手"},
{"role": "user", "content": "用一句话解释什么是 token"}
]
}'
Claude Messages(Anthropic)
Claude Cli的请求格式
curl https://api.anthropic.com/v1/messages \
-H "x-api-key: $ANTHROPIC_API_KEY" \
-H "anthropic-version: 2023-06-01" \
-H "content-type: application/json" \
-d '{
"model": "claude-sonnet-4.6",
"max_tokens": 256,
"messages": [
{"role": "user", "content": "用一句话解释什么是上下文窗口"}
]
}'
Gemini(Google Generative Language API)
谷歌Gemini的接口
curl "https://generativelanguage.googleapis.com/v1beta/models/gemini-3.1:generateContent?key=$GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"contents": [
{"role": "user", "parts": [{"text": "用一句话解释什么是 RPM/TPM"}]}
]
}'
提醒:不同平台对模型名(
model)和接口路径的命名会有差异;如果你用的是中转站,通常会提供一个“OpenAI-compatible base URL”,此时把上面的 OpenAI URL 换成它的 base URL 即可。
3) 从哪里用 API(官方 vs 中转)
-
官方直连:链路最短、规则清晰、合规边界更明确;缺点是你要分别管理多家 Key/账单/SDK,并且跨厂商“自动降级/切换”要自己做。使用美元结算,一般是找人拼车,如果用量不大就很贵,另外需要稳定的外网环境。
-
中转站/聚合(例如 OpenRouter、或者国内的野站):一套 Key 访问多家模型,接口形态往往做了“统一”,也可能提供路由/降级与用量看板;缺点是多一跳,数据会经过“中转 + 下游 provider”,需要额外关注隐私、日志与计费口径。国内的中转,通常比较便宜,不需要外网环境,但服务通常不稳定、可能跑路。
4) 额度/限额怎么理解
- token:可以把它理解成“模型读写文本的计量单位”(不是按字数精确计费)。
- 中文通常是“几个字/词”约等于 1 个 token(不精确);英文更接近“词的一部分”。
- 计费一般看 输入 token + 输出 token;别忘了工具调用/结构化输出等也会计入。
- 同一段内容,带上大量历史对话/代码/日志,输入 token 会迅速膨胀。
- 上下文窗口:单次请求允许的总 token 上限(大致可以理解为:历史对话 + 本次输入 + 生成输出的总和)。越大通常越贵也越慢;超限常见表现是报错或被截断。
- 预算/额度上限:某一段时间内的最大使用量,常见有日限/周限/月限/项目限额/Key限额;官方和中转站都有限额。
- RPM/TPM:每分钟请求数/每分钟 token 吞吐限制。不同平台口径不同,也可能“按模型分别限速”。
第三部分:上手流程
- 先选一个客户端(CLI / IDE 扩展 / AI IDE)。
- 再选 API 来源(官方直连 vs 国内中转)。
- 安装和配置完后,询问AI,看看能否正常回应。
以Cline为例:
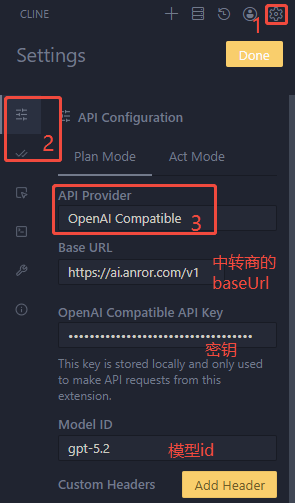
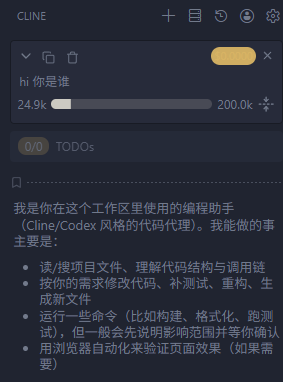
第四部分:开发进阶(MCP、Skills、Spec、sub-agents)
这一部分重点介绍几类更偏“工程化”的能力:用 MCP 把模型接到真实工具和数据源上,用 Skills 固化可复用的工作流程,用 Spec 让需求变成可执行的规范,再通过 sub‑agents 让多个专职 agent 分工协作。
注意,使用mcp、skills、spec会占用更多的模型上下文,应该只保留有用的工具.建议保持充足的模型上下文空间,否则效果只会适得其反。
MCP(Model Context Protocol)
是什么:由 Anthropic 在 2024 年 11 月推出的开放标准,定义了 AI 模型如何安全地连接外部工具、数据源和服务。可以把 MCP 理解成"AI 版的 USB-C":一套统一的协议让AI能接入任何数据与使用工具。
关键能力:
- 工具(Tools):AI 可以调用的函数,比如查询数据库、调用 API。
- 资源(Resources):文件、数据库记录、API 响应等上下文信息。
- 提示(Prompts):预定义的工作流和模板。
推荐的MCP服务器(举例):
exa:接入 Exa 的实时网页搜索 / 爬取能力,用来查询网络实时信息和调研工作。chrome-devtools:把 Chrome DevTools 暴露给 AI,支持在真实浏览器里看 DOM、控制台日志、网络请求和性能数据,特别适合前端联调和排查样式/交互问题。context7:为项目依赖的库/框架拉取最新、版本匹配的官方文档,减少过时 API 和幻觉用法。filesystem:让 AI 有受控地访问本地或远程文件系统,可读写文件、搜索目录树,适合做代码基/配置的批量操作。serena:提供语义级代码检索和编辑能力,类似“把高级 IDE 的跳转/重构能力通过 MCP 暴露给模型”,让ai不需要阅读全部代码,也能找到变量、函数的位置,目前与Claude code的LSP能力平替。augment-context-engine:Augment Code 的 Context Engine MCP,把大仓库/多仓库的语义索引作为上下文提供给 Agent,用于复杂工程的检索和导航。可以让ai不用大规模的读取、搜索项目代码,直接通过mcp找到具体功能的代码块。react-grab-browser:基于浏览器的页面抓取/选择工具,帮助 AI 从真实网页中提取组件结构或 UI 片段,常用于前端重构和“照着现有页面实现”。可以直接从浏览器复制出项目的代码位置,方便需求描述和节省token,适用于react项目。mysql-mcp:可以直接让ai连接到MySql数据库,拥有数据库操作的能力。
何时用:给ai提供工具,让它具备更丰富的能力。
Skills(技能库)
是什么:通常由 Claude 推出,是一组"可复用的高级指令",打包成可随时激活的"程序手册"。不同于一次性提示词,Skills 会在需要时被自动加载,帮助 AI 记住你特定领域的规则、流程和最佳实践。如果说mcp是工具,则skills则是经验。
能做什么:
- 固化公司的代码规范。
- 自动化代码审查清单。
- 多步工作流。
常见 Skills 类型:
- 代码审查:自动检查 SQL 注入、权限验证、错误处理。
- 规范指南:确保ai写的代码符合公司风格。
- 部署流程:提醒 AI 遵循你的上线前检查清单。
- 测试覆盖:自动补充单侧、E2E 测试。
何时用:有一套你经常要重复的指令或审查流程时;想让 AI 记住某领域的最佳实践而不用每次都讲解、试错。
Spec(规范驱动开发)
是什么:Spec-Driven Development(SDD)要求先写清楚“要做什么、为什么、边界在哪”(机器可读的规范),再让 AI 和代理按规范拆解任务、写代码和测试。相比直接聊天写代码,它更像“先出设计稿,再开工”。
与 Vibe Coding 的区别:
- Vibe Coding:一句"帮我写一个登录页面",AI 自己脑补需求和边界,生成的代码不可控,而且可能要重新生成很多次才能满足需求,后续维护难。
- Spec:先把登录/鉴权方式、字段校验、错误处理、埋点/监控等用规范、需求文档说清楚,AI 只是按图施工,通常一次性生成完毕然后零散修改,后续通过需求、代码文档来维护。
常见 Spec 载体:
- YAML / JSON / 结构化 Markdown:描述模块、接口、约束、验收条件。
- Gherkin(BDD):
Given / When / Then形式的行为规范。
常见 SDD 工具 / 框架:
- GitHub Spec Kit(开源):目前事实上的开源 SDD 标准。通过 CLI 和
/specify → /plan → /tasks → /implement四段式命令,把一份规范接入 10+ 种 AI 助手(Claude、Copilot、Cursor、Gemini 等),做到“一份 Spec,多种 Agent 复用”。 - OpenSpec:轻量、供应商无锁定的 Spec 框架,使用标准的 YAML / JSON / Markdown 存在仓库里,不依赖外部服务,更适合想低门槛尝试 SDD 的团队。
- AWS Kiro:把 SDD 做进自家 AI IDE 的方案。四阶段工作流(需求 → 设计 → 规划 → 执行)全部在 IDE 内完成,结合实时规范校验、规范感知补全等能力,适合 AWS 生态和愿意接受新 IDE 的团队。
- Superpowers:偏“加强工程纪律”的工具,为 AI 助手强制引入 TDD / 规划 / 复盘等流程,避免 agent 直接“上来就写代码”,常与 Claude Code 配合使用。
- Trellis:在 Spec 上做了分层和索引,让规范既能渐进式披露(类似 Skill),又不会丢失关键上下文;配套脚本把一整套规范化对话流程变成自动注入的 Skill 工作流;内置更强的 Todo 管理(用 JSON + Markdown 记录优先级、负责人、关联分支/worktree);整体更加轻量,适合团队、新手使用。
何时用:
- 需求复杂、涉及多服务/多模块,需要多人协作和长期维护时。
- 希望对 AI 生成的结果有可审查的依据(不是“感觉差不多”)。
- 需要把“如何用 AI 开发”的经验沉淀到仓库里(规范 + 流程),而不是散落在一次性的代码生成记录里。
一个常见节奏是:写 Spec → 用工具生成方案和任务 → 让 Agent 按 Spec 产出代码和测试 → 人工按 Spec 和用例验收 → 根据反馈同时更新 Spec 与实现。